
こんにちは、さち です。
突然ですが、「正規表現」って知っていますか? 簡単に言うと、文章などから特定の文字を探し出す仕組みです。
正規表現はプログラミングで使うイメージが強いですが、実は次のような場面で使えることもあるので、プログラミングをしない人にも役立ちます。
- テキストエディタの「検索」「置換」
- ツイッタークライアントのなどの「ミュート」
- 5ちゃんねるブラウザの「NGワード」
そうは言っても、『書き方が難しそう』『ワイルドカードと何が違うの?』と不安を感じる人もいると思います。
そこで、今回は「正規表現」の記述方法についてまとめていきます。
「メタ文字」を使いこなそう
「正規表現」には「メタ文字」と呼ばれる特殊な文字があります。
「メタ文字」は、ワイルドカードと同じように任意の文字列(文字のられつ)を表現できますが、ワイルドカードよりも具体的で細かな指定ができます。
「メタ文字=ワイルドカードのスゴイ版」と思って下さい。
正規表現を使いこなすには、この「メタ文字」の使いこなしが必須です。
次項から「メタ文字」を紹介していきますが、全部を覚える必要はありません。簡単なものを使うだけでも、表現の幅がワイルドカードより格段に上がります。
よく使う「メタ文字」は自然と覚えられるので、気楽にいきましょう。このページをブックマークしておいて、忘れたときに見返せば良いだけのことです。
正規表現については私もまだまだ勉強中です。誤りがありましたら教えて頂けるとありがたいです。
メタ文字の種類
「メタ文字」にはいろいろな種類があります。それぞれの意味で分類して見ていきましょう。
1. 文字の種類

どの「文字の種類」が使われているかを指定するメタ文字です。
ただし、このようなメタ文字であらわせるのは「1文字」だけ。文字数の指定には、次に紹介する繰り返しを意味するメタ文字を使います。
. は任意の一文字
.(ドット) は任意の一文字をあらわします。.(ドット) はよく使うので、これだけは絶対に覚えておきましょう。
- は文字コードの範囲
ちなみに、-(ハイフン) を使った表記は、「文字コードが ○○○ から △△△ までの文字」という意味。
「ひらがな」「カタカナ」のスタートが ぁ ァ といった拗音(小さい文字)である理由は、その文字の種類の文字コードが拗音からはじまるからです。(「半角カタカナ」も同様)
2. 繰り返し
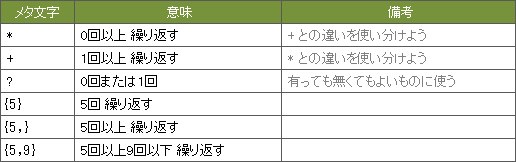
文字の「繰り返し」を指定するメタ文字です。
例えば、数字を1回以上繰り返す(=1桁以上の数字)という正規表現は、[0-9]+ のように記述します。
* と + の違い
* + による繰り返しはよく使います。
* は「0回以上」、+ は「1回以上」の繰り返しという違いがあります。この違いは意外と重要なので意識して使い分けましょう。
意外と便利な ?
? は意外と便利です。
例えば「http」と「https」両方に一致させたい場合、「s」は有っても無くてもいいものなので、https? のように記述します。
また、jpe?g のように記述すれば、「jpg」と「jpeg」両方に一致します。
X回"以上"繰り返すとき
「X回以上繰り返す」という記述には注意が必要です。
例えば、{5, 9} のように「 ,(コンマ)」の前後にスペースを入れると正常に動かないことがあります。
コーディングのクセで入力しないように気をつけましょう。
3. 位置(先頭・末尾など)
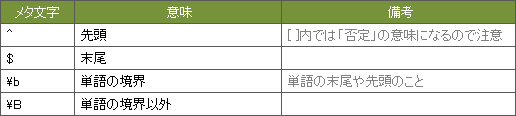
文字列がどの「位置」にあるかを指定するメタ文字です。このような機能を「アンカー」と呼ばれます。
先頭 ^、末尾 $ だけで大体間に合う
基本は、先頭,末尾 を意味する ^ $ を知っていれば大体何とかなります。
例えば、先頭が「http」からはじまる場合は ^http、末尾が「html」でおわる場合はhtml$のように記述します。
[ ] 内の ^ は否定の意味
[ ] 内にある ^ は否定の意味になるので注意。
例えば、^[0-9] は数字からはじまる文字列という意味ですが、[^0-9] は数字以外の任意の1文字という意味です。
\b の「単語の境界」とは?
「単語の境界」とは、単語の先頭や末尾のことです。
例えば、e\b とした場合「cute and clever elichika」で該当するのは、「cute」の末尾の「e(赤字部分)」だけで、他の「e」は該当しません。
逆に、\be とした場合「cute and clever elichika」で該当するのは、「elichika」の先頭の「e(赤字部分)」だけです。
4. 選択(AまたはB)
![]()
「AまたはB」のような「選択」をあらわすメタ文字です。
例えば、正規表現で No(zomi|ntan) と書いた場合、「No」の続きは「zomi」と「ntan」から選択することになり、「Nozomi」と「Nontan」という2つの文字列をあらわします。
普通なら2つの文字列を別々に書く必要があるものを、一つの正規表現であらわせるわけです。
ちなみに、No(zomi|ntan|nchan) のように複数使うこともできます。
5. エスケープ

正規表現で特殊な意味を持つ .(ドット) などの「メタ文字」は、そのままだと「普通の文字」として使うことができません。
例えば、普通の文字列「www.lovelive.jp」を表現するには、www\.lovelive\.jp のように .(ドット) の前に \ を書く必要があります。
このような方法を「エスケープ」と言います。
\ もエスケープが必要な文字
\ 自身も直後の文字をエスケープする「メタ文字」なので、普通の文字として使うには \\ と書く必要があります。
エスケープが必要な文字はプログラミング言語で変わる
使用するプログラミング言語によって、「エスケープ」が必要になる文字が微妙に違います。注意して下さい。
例えば、JavaScript では / で囲んだ部分は「正規表現リテラル」になるので、この中で / を表すには \/ とエスケープが必要です。
6. その他のメタ文字
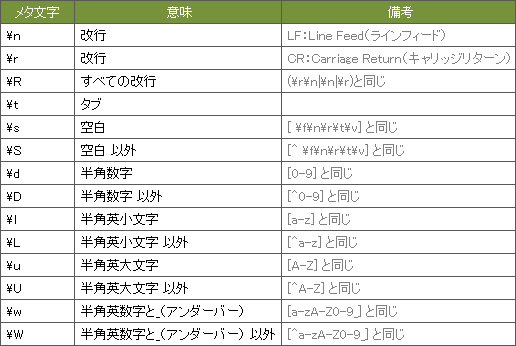
特殊な意味を持つメタ文字です。
「余白」系だけで大体間に合う
「改行」「タブ」「空白」を意味する \n \t \s を知っていれば大体は何とかなります。(アルファベットを大文字にすると「否定(~以外)」の意味になる)
\d \l \u \w などは記述を省力化できて便利ですが、文字種の指定でも間に合うので無理に覚えなくてもいいです。
\R は未対応の場合も
\R は改行をまとめて指定できるので便利ですが、正規表現を扱う環境(テキストエディター・プログラミング言語)によっては使えない場合があります。
7. キャプチャ(使い回し)

カッコで囲むとその部分がキャプチャされ、使い回すことができます。少し複雑なので、最初は無理に使わなくて大丈夫です。
任意の文字の繰り返しを探せる
例えば、([a-z]+)_\1 とした場合、「ma_ma」「pa_pa」「waku_waku」など同じ文字列が連続したものを探せます。
「置換」にも使える
「置換」ではキャプチャした内容を出力にも利用できます。
例えば、「検索」を ([a-z]+)_\1、「置換」を $1×2 とすると、「ma_ma」は「ma×2」、「waku_waku」は「waku×2」に置換できます。( $1 でなく \1 と記述する場合もある)
8. 先読み・後読み(含む・含まない)

特定の文字列を含む/含まないようにする時に使う記述方法です。これも少し複雑なので、最初は無理に使わなくて大丈夫です。
「先読み」の「先」は、今いる場所より「先」の文字を読むことを意味します。つまり、「先読み=直後に○○という文字列がある」という意味です。同様に、「後読み=直前に○○という文字列がある」という意味です。
記述の形式としては、? の後に < が有れば「後読み」、無ければ「先読み」です。さらに次に続く文字が = なら肯定(含む)、! なら否定(含まない)です。
機能は「位置」を探すことだけ
「先読み」「後読み」で行うのは、条件を満たす「位置」を探すことだけ(アンカー)です。先頭/末尾をあらわす ^ $ と同じ仲間だと思って下さい。
例えば、肯定先読み Yo(?=hane) を使った場合、「Yohane」は Yo の直後に hane を含むので一致しますが、「Yoshiko」には一致しません。
ただし、肯定先読みの機能は「位置」を探すことなので、抽出されるのは「Yo」だけです。
例えば、行末にある空白だけを抽出したいときは \s+(?=\R) とします。( \R はテキストエディター・プログラミング言語によっては使えない場合があります)
「\」が付くメタ文字が機能しない場合
例えば、JavaScript の「文字列リテラル(" や ' で囲んだ文字列を書く部分)」では、正規表現の \n \d \\ などが正常に機能しません。
そのような場合、\ を \\ に置き換えましょう。\n → \\n,\d → \\d,\\ → \\\\ といった感じです。これで正常に機能するはずです。
var re = new RegExp("\d+円");//動かない
var re = new RegExp("\\d+円");//動く
機能しない原因
なぜこんなことが起きるのでしょうか?
JavaScript で alert("こんにちは\nさようなら") と書くと、文字の \n は「改行」になりますよね。つまり、JavaScript の文字列リテラルでも \ はメタ文字なんです。
これと同じことが前述の \d にも起きますが、JavaScript には \d という表記が存在しません。
その結果、\d はエスケープとして処理され d になり、これが正規表現に送られます。(同様に、\\ は \ に変換されてから正規表現に送られる)
このような理由で、正常に動かないわけです。
文字列リテラルに正規表現を記述する場合は、そのプログラミング言語のメタ文字に注意しましょう。
「正規表現リテラル」を使った方が安全
「文字列リテラル」ではなく「正規表現リテラル」を使えば、このような現象は起きません。(JavaScript では / で囲んだ部分が正規表現リテラルになる)
// 文字列リテラルを使った記述
var re = new RegExp("\\d+円");
// 正規表現リテラルを使った記述
var re = /\d+円/;
関連記事

コメント